気象庁が作成している天気予報ガイダンスについて述べた次の⽂(a)〜(c)の正誤の組み合わせとして正しいものを,下記の①〜⑤の中から⼀つ選べ。
-
(a) 天気予報ガイダンスは,数値予報モデルの系統誤差を統計的に補正することができるが,初期値の誤差に起因するランダム誤差を補正することは困難である。
-
(b) カルマンフィルターを⽤いたガイダンスでは,実況の観測データを⽤いて予測式の係数を逐次更新しており,局地的な⼤⾬など発⽣頻度の低い現象でも適切に予測することができる。
-
(c) ニューラルネットワークを⽤いたガイダンスは,⽬的変数と説明変数が⾮線形関係をもつ場合にも適⽤できる⼀⽅で,予測結果の根拠を把握することは困難である。
| (a) | (b) | (c) | |
| ① | 正 | 正 | 誤 |
| ② | 正 | 誤 | 正 |
| ③ | 正 | 誤 | 誤 |
| ④ | 誤 | 正 | 誤 |
| ⑤ | 誤 | 誤 | 正 |
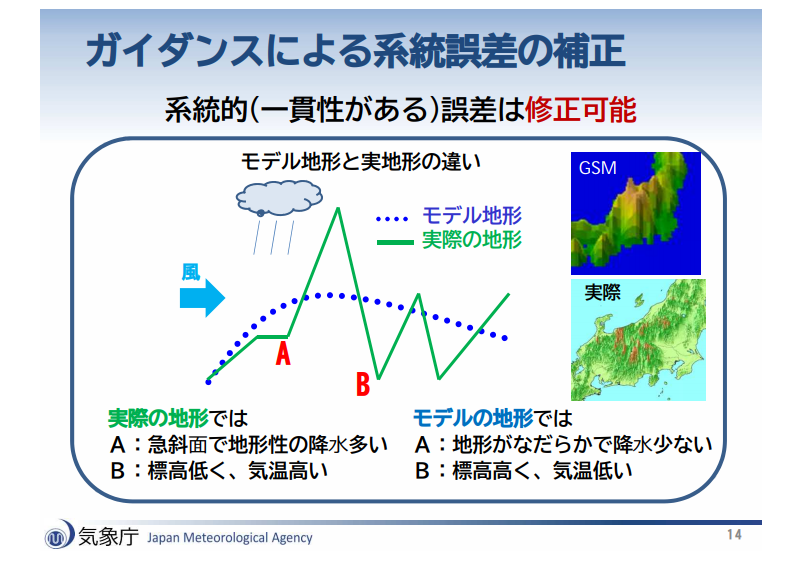
これは正です。
「系統誤差」とは「地形による誤差」などが当てはまります。
山の影響をイメージするとわかりやすいかもしれません。山は今日でも明日でも高さが変わらないので、統計的に補正することができます。
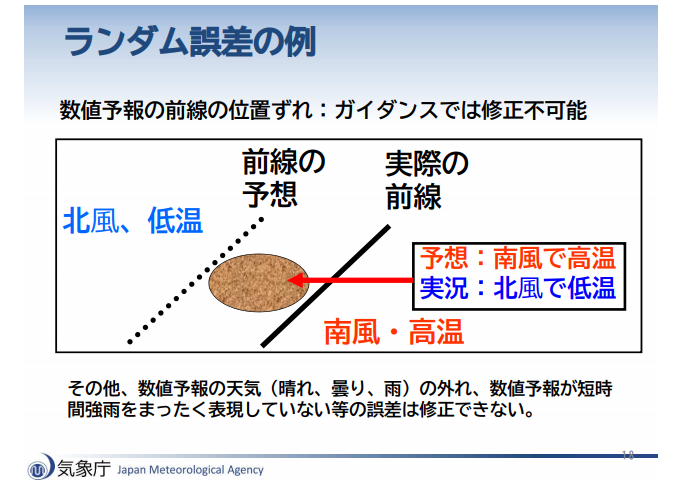
一方「ランダム誤差」とは「初期値の誤差に起因する誤差」で、例えば「前線の位置のズレ」などが当てはまります。
前線が通過する地域を数値予報モデルで予報する際、最初に設定する初期値がそもそも間違っていることがあります。
この場合、誤差があるかどうか、あったとしてどのくらいの誤差になるかは、そのつど変わります(先週の前線と今週の前線でズレ方が異なる、というイメージ)。
よって誤差を補正するのは難しいです。
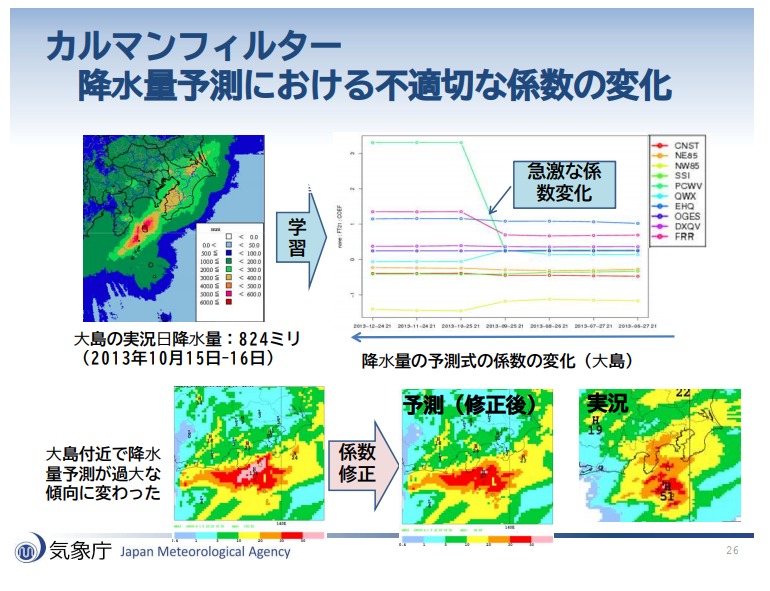
これは誤です。
カルマンフィルターを⽤いたガイダンスでは、局地的な⼤⾬などを予測することは難しいです。
ガイダンスとカルマンフィルターについては以下の通りです。
■ガイダンスの概要
ガイダンスでは数値予報データと実況の観測データを用いて、統計的に予測式を作ります。そのために、まず過去の数値予報データと観測データを用意します。
用意した数値予報データから、気象や統計の知識を基にして、観測と因果関係が強い要素を抽出して変数を作ります。
この変数を説明変数といいます。また、観測データを目的変数といいます。2つの変数を用いて予測式を作成します。(参考:気象庁HP「ガイダンスの解説」)

(気象庁HPの画像を加工)
■カルマンフィルター
ガイダンスでは説明変数と目的変数を用いて、何らかの方法で予測式を事前に作成しますが、この方法のひとつがカルマンフィルターです。
カルマンフィルターの特徴は以下です。
【メリット】
- 係数更新(逐次学習)型(予測式の係数を随時更新することができる)→ 短い時間で変化する気象現象(気温、風、降水量など)に使える。
- 予測式が線形(線形:一次関数的な関係、グラフにすると直線になる)→ 説明変数の変動がどの程度、予測結果に影響を与えているか把握しやすい。
- 季節変化による数値予報モデルの誤差や変更に対応しやすい。
【デメリット】
- 係数が更新されるので、予測特性を把握することが難しい。
- 頻度が少ない大雨や強風などは、係数更新型によって必ずしも予測精度が向上するわけではない。
※以下のように局地的大雨によって数値予報データが過大な値となったとき、過大なデータを基にして係数を更新して変数を作ってしまうので、その後の予報が過大なものになります。(ゲリラ豪雨みたいに一時的な雨でも、その影響がこの先も続くと判断して係数を更新しちゃうイメージです。)
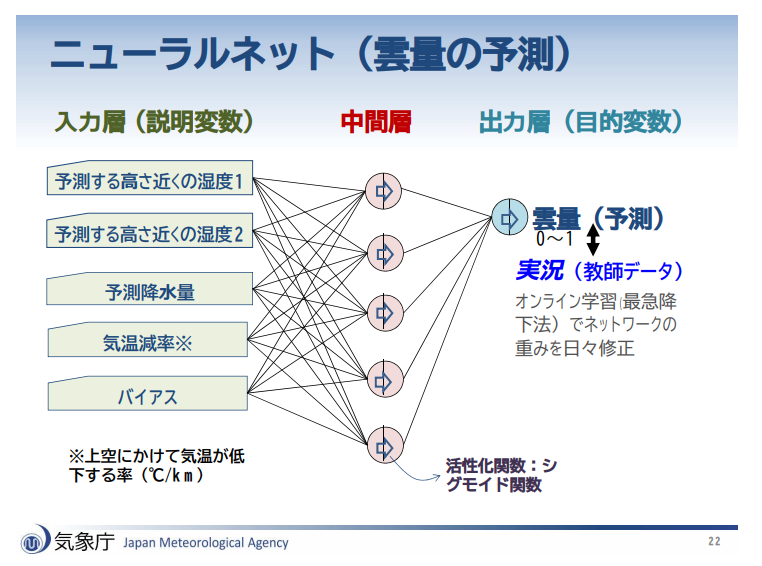
これは正です。
ニューラルネットワークについては以下の通りです。
■ニューラルネットワーク
ガイダンスでは説明変数と目的変数を用いて、何らかの方法で予測式を事前に作成しますが、この方法のひとつがニューラルネットワークです。
ニューラルネットワークは、説明変数と目的変数の関係が線形でない場合でも取り扱うことができます(線形:一次関数的な関係、グラフにすると直線になる)。
線形でない場合でも使えるというメリットがある一方、予測式が線形でないため、説明変数と予測結果の関係を把握するのが難しくなります。